10 minute read
What are some of the challenges of multi-channel delivery?

Warren Bickley
Director of Engineering

Multi-channel delivery in 2022 goes hand in hand with headless architecture; headless architecture is the new normal for organisations and technical products of all sizes, separating core business logic into one or more APIs and having individual deliverables (typically interfaces such as websites and mobile apps) which interact with those APIs.
Headless architecture is widely accepted as a sensible default choice for businesses looking to scale their technical success with increasingly more channels over time, at the cost of a typically slightly longer delivery timeline on the first implementation.
Whilst headless development has its advantages for scaling, it comes with its own challenges.
Development can be very repetitive
Redefining definitions, rules, and logic across a headless stack can become repetitive and tedious. Where inputs and responses might be defined within headless API validations and serialisers, consuming interfaces will also need identical definitions. Prior to the popularity of JavaScript, this was seldom often sharable due to platform and implementation differences across deliverables.
Validation logic for instance within a headless setup is typically fairly hybridised, with interfaces doing some of the work before kicking data off to an API for a final check prior to an action being completed. There are two reasons for doing this; minimise the number of API calls, and decrease the time it takes for the user to get feedback. In order for this to work seamlessly, the basic validation rules on the interface need to match what is happening in the API layer lest you run into validation check mismatches whereby errors are thrown in the interface which might not get thrown by the API.
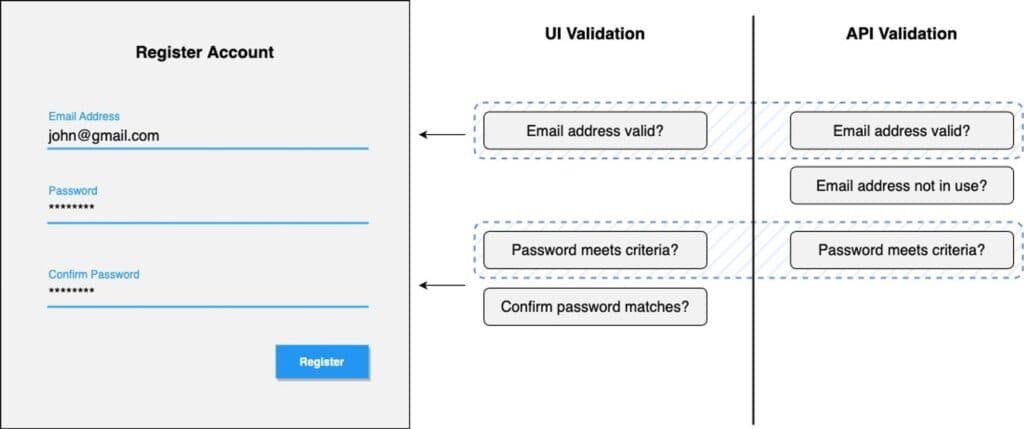
Take a simple registration form for example. Whilst the user is engaging with this interface we want to let them know if their inputs are valid, we can do this in real-time within the interface. When the user hits submit, those same validation rules are also run on the API alongside additional checks for account collisions. If the rules on the API layer change, in terms of email address validity, password criteria, or additional checks, a corresponding change has to be made on all-consuming interfaces.
It’s easy to see how on a screen with a more complex interface, and with multiple delivery channels, how this repetition and margin for error can increase dramatically.
Disciplines block each other
Within headless teams that are delivering a single product together, changes required across the stack mean individual tasks are often blocked or impaired by resource requirements. This can be a pinch point during active development; often needing to scope API changes to a high degree of certainty and well ahead of interface changes.
This is particularly noticeable in teams where the stack differs between the API and user interfaces, as even where a UI or API engineer does have the autonomy to make changes across the stack they may not have the relevant understanding or experience to do so.
This means that where an interface change requires API changes, there can be an unnecessarily long feedback loop:
Scope out the change for an API engineer or team
Code review
Testing
Publishing the work to a development or staging environment
Testing the interface change end-to-end and integrating
When teams maintain these shared definitions individually within their API and corresponding interfaces, there is an increased risk that the integration between them will break and fail (often with little warning) and this often isn’t realised until end-to-end testing.
What are some of the challenges when building Enterprise JavaScript applications?
Building applications in JavaScript is incredibly fast, this is largely down to a broad array of tools and packages dedicated to reducing effort and maximising output. Constant innovation within the space has brought about build tools like Webpack and TypeScript which serve to automate a tonne of work and increase reliability. Like any language, framework, or toolset; it has its challenges.
Setting up new JS projects can be painful
The broad range of exceptionally capable tools and packages we have available within the JavaScript ecosystem does come at a cost; setting up a new project is slow and cumbersome. Wrangling multiple build tools together can be painful and any minor incompatibilities can block engineers for days. Configuring linters and code fixers (particularly when integrating with TypeScript) almost never works the first time and the nuances between configurations in a local IDE versus CI can be a pain to untangle.
Whilst painful, it is also a fantastic opportunity for innovation. Expect teams to invest time in understanding the latest tools, or even just the latest version of the tools already at their disposal. Innovation within Open Source JS tooling moves so quickly that a fresh set-up can almost always add value. This is why teams probably shouldn’t maintain their own application boilerplate; maintaining one only to use it once every few months (at most) simply isn’t worth the foreseen cost-saving, especially as that saving prevents them from moving with rapid technological changes.
Taking a fresh approach to project setup when combined with existing experience also presents the opportunity to identify technology changes which might retrospectively fit into existing projects. These changes might improve the developer experience of those projects and as such contribute back to the continual accelerated delivery of enterprise JS applications within their organisation.
Maintaining dependencies gets overlooked
JavaScript is often shamed for its “dependency hell”; its greatest asset, a booming open-source culture, is frequently portrayed as a viper's nest of unknowns that engineers casually exploit with no regard for the implications.
These criticisms are founded on historical issues with the JavaScript default package registry, npmjs.com. Debacles with the "left-pad", "event-stream", "is-promise" and "colors" packages have served to harm the trust engineers have in the package ecosystem and acted as pillars to besmirch JavaScript as unsafe; this trust however was always misplaced. These incidents have served to make engineers more considerate of their third-party dependencies.
These dependency issues aren’t exclusive to the JavaScript ecosystem, dependency chain attacks exist in almost every package management ecosystem. Like others before it, NPM has taken time to mature and implement better processes and security practices.
The real challenge with dependencies is that the vast array of them and the frequency at which they are updated can make periodic updates impossible; release frequency for actively maintained dependencies can vary from multiple times a week to every 6 weeks. Based on this, it is often the case that after 8 weeks a significant portion of your direct dependencies may have updates available. After 6 months of neglect, updating the dependencies of a project could become an insurmountable task requiring significant investment.
How can multi-channel JS development be accelerated?
JavaScript's superpower is the ability to write the same code for our APIs as most of our interfaces. With the right architecture and team structure a small nimble team of cross-stack JavaScript engineers can achieve what would otherwise require a multi-functional team of engineering specialisms, done well there are zero compromises on deliverable quality with a huge reduction in both work and required communication.
Share code across the product stack
Modern user interface development sees us now doing a lot of work on the UI that previously would have run exclusively on the API, particularly with regard to input validation. This means that within a lot of ecosystems, we end up duplicating schemas, validation rules, types and even logic across the application stack; any potential inconsistencies in these duplications can introduce risks. For every additional interface interacting with the same API, that risk is drastically increased.
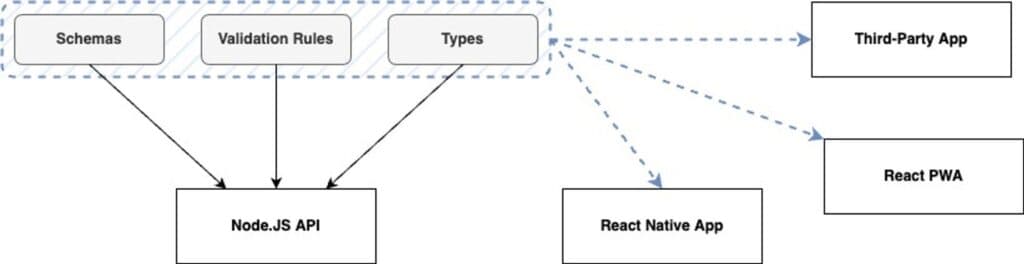
Instead of duplicating this code, it can be shared across the APIs and interfaces as a source of truth. Within an entirely JavaScript ecosystem this is fairly straightforward; achieved either with a Monorepo encapsulating all packages or by publishing to a package registry.
If you’re developing an API alongside your deliverable UIs, as is often the case with headless development, then the former approach of working within a Monorepo is generally superior to publishing packages to a registry. Changes are reflected across the stack instantly and this allows engineers to tweak either side as required as opposed to waiting for each other to implement and publish changes. This offers a superior developer experience and improves cross-stack awareness and capabilities with all engineers.
Derive SDKs and other packages from API code
An alternative approach is to generate consuming packages from API code, whilst this requires much more configuration and a strictly declarative approach to API definitions it does grant far more capabilities. This approach is particularly well suited to APIs which require third-party availability given it can output more than just JavaScript or TypeScript packages.
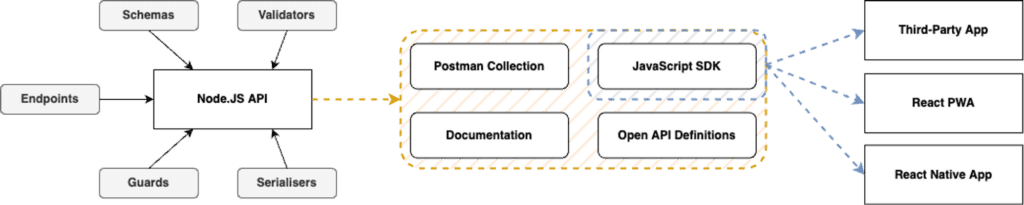
With an approach such as this, documentation and API definitions are generated from API code so require little to no maintenance. The always up-to-date documentation, debugging collections, and API definitions, make it much easier for anyone to integrate with the API (internal and external) - even if they’re not using JavaScript.
Having all of these resources available at the start of a new integration would enable teams to get new projects up and running incredibly quickly, and enforce consistency via end-to-end type-safety. In contrast to solutions currently available within the JavaScript ecosystem, it would enable teams to develop APIs which are decoupled from their web deliverables but keep the same level of reliability across the stack and further.
Implement quality gates into CI processes
Quality gates exist to identify a vast array of preventable issues at different points in the software delivery lifecycle; one of the most valuable times to run these checks is before code is committed to primary branches (depending on your workflow). This often means running a range of them on pull requests and preventing branch merges unless all checks pass. This functionality is available on all the major repository management platforms and is commonplace amongst most organisations with a strong engineering team.
Examples of some of the checks which might run, depending on the project and stack, might be:
Test suites pass: Do all of the tests in the project code pass?
Code coverage requirements are met: Does the test coverage meet the requirements set out in the project?
Output bundle size meets requirements: Is this bundle a reasonable size? This is particularly useful for client-side packages which are shared such as UI libraries for design systems.
End-to-end type safety: Do the types emitted by the API compile in consuming packages such as UI’s without issue?
Code quality checks: Do tools such as Sonar Qube report suitable code quality?
Dependency vulnerability reports: Are there no known vulnerabilities in any included dependencies?
Automatically maintain dependencies
There are a handful of tools available which are designed to integrate with any Git repository to automatically attempt to upgrade dependencies, coupled with strong quality gates this can be seamless and drastically cut down any manual maintenance.
Two tools which have become increasingly popular are Renovate and Dependabot. Both, when configured to do so, automatically raise pull requests for individual dependency updates - with the latter tool focussing only on dependencies which have vulnerabilities. These tools can be configured to automatically merge in these updates providing quality gates pass.
Anatomy of an enterprise cross-stack solution at Griffiths Waite
Griffiths Waite has maintained both business and individual welfare critical financial and government applications spanning multiple decades, this puts a unique perspective on their approach to developing with Open Source solutions within the JavaScript ecosystem.
Type safety matters
Building and maintaining large-scale type-safe applications, previously with Java, would have been orders of magnitude more difficult without a type-safe language. It wasn’t long after Griffiths Waite started developing JavaScript solutions that the decision to move to TypeScript was made; a sensible decision given TypeScript leapt past Java this year in terms of most commonly used languages by professionals (according to the Stack Overflow 2022 survey).
Move faster with Monorepos
Where the deliverables of a project change together and in relation to each other, for example within a dedicated headless architecture, a monorepo enables teams to move faster.
In instances where a team (or teams) maintain both an API and web deliverable in a multi-repo setting, it is often the case that teams block each other for prolonged periods of time waiting for changes to make their way through the merge process or alternatively having to tinker with multiple-repos. With a monorepo, engineers can jump on the same branch and run all the changing, moving, parts together - allowing for closer collaboration on tasks that span the stack.
The monorepo approach doesn’t just enable teams to work together better either, it gives individuals autonomy to work across the stack which both gives them greater variety in their work and reduces context-switching for anyone who might have been required to support.
Reduce run time dependencies
Sharing code across deliverables through a monorepo or package publishing (especially useful for sharing externally) lets teams reduce the amount of run-time dependencies by shifting them into build time packages. This could be anything ranging from validation endpoints to shared resources.
Build with, not on
Technology moves fast, and JavaScript is no exception. The JavaScript ecosystem is however built to handle this pace incredibly well with the open source community keenly focussing on tools and packages, not frameworks. Where frameworks are used, they are often light enough that they are relatively easily replaceable.
Whilst having to bolt your own solutions together can be painful at the start of a project, it enables teams to swap out any given part of a solution whole-hog or piecemeal down the line. Done well, JavaScript projects can evolve with technological changes and the open source nature of the ecosystem lets engineers pull apart application dependencies for carving out easier migration paths.
Summary
Thanks to its ability to run anywhere and the exponential increase of web-capable devices, the JavaScript ecosystem is going to continue to be the go-to place for architecting new cross-stack multi-channels solutions at startups, scale-ups and enterprises alike. The developer experience and code-reduction capabilities of it makes it the right choice for teams who want to move fast and deliver robust solutions.
Product Development





